Deep Dive
18 July 2018 / /
The Time in China
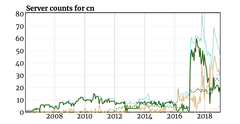
China has the largest population of Internet users. And of the hundreds of millions, even billions of devices in China, many of them rely upon the NTP Pool Project to keep their clock in sync.
After a successful drive to increase the number of NTP servers in the China zone at the start of 2017, 2018 started with a plummet. Whether this was due to attrition, lack of enthusiasm, or other factors is unknown. But gradually there were fewer and fewer servers for the vast population, until only a handful remained. The challenge for those server operators was how to continue providing NTP given the incredible traffic levels and rate of queries that participating in this zone brings.
One of the many challenges is dealing with the raw number of packets per second. Any firewalls performing connection tracking would quickly be swamped with the sheer number of flows (many of which could be short-lived). Therefore it is imperative to not track connections to UDP port 123. We achieved this by running dedicated NTP VPSs as a virtualised network function with no state tracking:
# excerpt from /etc/iptables/rules.v4
*raw
:PREROUTING ACCEPT [0:0]
:OUTPUT ACCEPT [0:0]
-A PREROUTING -p udp -m udp --dport 123 -j NOTRACK
COMMIT
This worked well early on in our participation in the CN zone. But as the number of participants in the zone fell, the CPU load increased. Eventually, even though each VPS had multiple cores allocated, the single-threaded ntpd process started to become the bottleneck. Throwing CPUs with higher clock rates and more per-clock performance only got us so far: then the number of packets per second going to one physical host and its virtual switch became the limiting factor. It was time to make a more clever solution.
Given the query-response nature of NTP, using connectionless UDP as its transport, it was perfectly suited to deploying in an anycast configuration. We could make use of equal-cost multipath (ECMP) routing within our network to distribute the incoming packets among a cluster of NFV VPSs. By assigning a common anycast IP address to a loopback interface of each VPS, ntpd on any of the hosts could receive requests and respond to them. All that remained was to make our routing layer distribute the packets across the cluster.
We run MikroTik Cloud Core Routers in front of our VPS clusters as gateways (and also as an attack-mitigation layer. Owing to limitations in the BGP implementation of RouterOS RouterOS not supporting ECMP we opted for a static route with a gateway check as follows:
/ip route add check-gateway=arp dst-address=46.227.200.24/32 \
gateway="46.227.201.100,46.227.201.101,46.227.201.102,46.227.201.103, \
46.227.202.104,46.227.202.105,46.227.202.106,46.227.202.107"
Here, the IP addresses 46.227.201.100 through 46.227.201.103 and 46.227.202.104 through 46.227.202.107 were assigned to the external interfaces of eight VPSs, each running on a different physical host. This ensured that we would balance the volume of packets across separate switch ports, LAGs, and virtual switches — as well as multiple VPSs which had separate cores.
We contributed two clusters in a similar configuration to the effort, one in the UK and the other in Switzerland, while the NTP Pool Project redoubled its efforts to increase the server count more locally within mainland China. With this arrangement we were able to serve hundreds of thousands of queries per second in aggregate — hundreds of megabits per second — fairly comfortably on modest hardware.