Case Study
28 November 2020 / /
How we helped Epix to mitigate a potential #FAIL
One of our clients, Epix Systems, recently had a hardware failure on one of their servers which hosts applications for their customers. Most of the customers didn’t notice that the server went down: in this post we’ll explain what the problem was, how the system coped, and what we had done to ensure that their system was resilient with high levels of redundancy.
Epix build job control and mobile working software that manages the full end-to-end processes of building maintenance for repairs and maintenance contractors in the social housing and facilities management sectors.
Servers are at the core of their service provision. For their customers the system is a critical component of service delivery, is in constant use by engineers recording details of their visits in real-time, also by back office staff managing workflows. Epix also provide integration between Epix customers and their clients, so it’s essential that they send and receive data between systems.
Any system downtime would severely impact the customers operations, which in turn would affect their own clients.
Epix originally approached Faelix a couple of years ago because they were losing patience with their existing hosting provider — they were not managing the two dedicated servers particularly well, and were unable to be specific about the software configuration which varied across each of the servers.
We examined their set up and talked to them about their future requirements and they commissioned us to install three new dedicated servers across two Manchester data centres, with Faelix providing a managed service.
Key aims of the new system were to:
- Create a resilient system
- Build a significant amount of redundancy to account for hardware failure
- Provide diverse connectivity routing
- Ensure that the machine configuration was easily replicable
We used SaltStack for configuration management, deploying several hundred Salt states to each server resulting in three identically configured servers.
We initially located the three servers in two Manchester datacentres to provide for diverse routing. When we established our presence in Leeds, we moved one of the servers. The servers are configured to mirror the systems in real-time, so we had a stable configuration that was resilient with a significant amount of redundancy.
In October 2019 we initiated some major incident planning with Epix. We ran a “fire drill” — a planned evacuation of one of their three hosting servers to see whether all their customers could run on two nodes. We planned the simulation to give us insight into how performance might be affected in the event of an actual hardware failure. We expected some subtle differences between the theory (take the load of the third server, divide it roughly evenly between the surviving two) and the reality because performance at load can be non-linear, with accelerating degradation as you approach I/O limits.
We found that the existing load ran acceptably on two servers, but with anticipated growth to Epix’s I/O and CPU load, more hardware should be considered. As expected, performance didn’t degrade linearly, and the existence of some very large and resource-hungry end users within Epix’s platform meant that we saw much higher I/O latency on the servers during the fire drill test.
We ordered a fourth server to ensure that there would be sufficient capacity for expanding the service, and servicing resource hungry clients. We also mitigated high I/O latency by installing NVMe drives in the existing servers, providing high speed data access, allowing us to reconfigure the database layer to have temporary tablespace (scratch area for sorting large query data, etc) on the non-replicated storage NVMe drives to acheive lower latency.
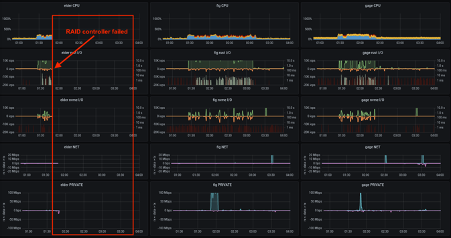
In July 2020 the RAID controller failed on one of the servers rendering it inactive. This could have caused serious problems for Epix customers and potentially severe data losses.
At 07:34 on the morning of the 16th of July one of our servers failed. At 07:56 the first customer noticed and called us; by 07:59 the customer was fully operational on a secondary server with no data loss. By 08:20 all customers had been notified individually and confirmed as fully working. Most of our customers were not aware that there had been a problem.”
Epix investment in a process of continuous improvement paid off — over three years we made a number of ‘marginal gains’:
- The servers are configured with RAID drives with DRDB (Distributed Replicated Block Device) which facilitates shared data storage by networked mirroring – the data was mirrored in real-time across the three servers located in different datacentres. This provided resilience in case of hardware problems.
- Each server has the exact same configuration. Saltstack automation tools to build our test and production servers, deploying several hundred Salt states resulting in three identically provisioned machines (and bringing additional servers into play is relatively easy).
- The four servers were located across three data centres in Manchester and Leeds – so that we had diverse upstream routing available when there are significant network outages, increasing our resilience in terms of network path and data replication across multiple datacentres.
- We increased the level and granularity of remote diagnostics and monitoring – monitoring software feeds updates to the Epix office. Audible alarms, emailed alerts and a large screen all give immediate warnings if systems are behaving unusually, highlighting performance problems that customers may be having, and often allowing them to intervene before customers are even aware that there may be a problem.
- We also mitigated high I/O latency by installing NVMe drives in the servers, providing high speed data access. This allowed us to reconfigure the database layer to have temporary tablespace (scratch area for sorting large query data, system log files, web service log files, static database files, PDA connection logs, old backup files etc) on the non-replicated storage NVMe drives to achieve lower latency – and thus faster server response times.
- When the faulty server was repaired, we located it at one of our London datacentres, to increase resilience further.